The Rundown
With a booming RSA, GDP growth of 2.7%, cooling inflation, a historic Presidential debate, and a $25 million ransomware attack that shut down U.S. car dealerships, it was an adventuresome Q2. With Black Hat just a week away and an unprecedented Presidential Election campaign that will determine the fate and deployment of a wide range of regulations, legislation, and programs focused on national and economic security, it is a tough time for anyone in the prediction business. But, looking back at Q2 can provide perspective on what could be coming in the second half of the year.
1. Venture Investment Remains Tame
The venture market did not see a reprieve from the macroeconomic forces that had plagued it in previous quarters. Venture firms set record highs of dry powder, neared record lows of deal volume, and waited in the wings for market uncertainty to ease.
2. Git-ing Code Locked Down
How well do companies manage controls around using hosted code repositories like GitHub? As software development has moved to the cloud, code repos represent a key attack surface. By definition, the code and documentation hosted in a version control system like GitHub are intellectual property of at least some elevated importance. In many cases, it’s extremely sensitive. Are organizations implementing security controls around these repositories that are proportional to the risk?
3. AI Regulation Discussion Going Back to Cali
The California State Senate passed California SB 1047, a bill to regulate companies developing “frontier AI models.” More specifically, should the bill pass the California Assembly in August before heading to Governor Newsom’s desk for signature, it will create a new state agency aptly named the “Frontier Model Division,” which would establish laws and safety standards. The bill’s intentions are good, but is it good for business, innovation, and American competitiveness?
4. Insurance Impact on Ransomware Attacks
Cyber insurance is critical in today’s threat environment. However, it could lead to more attacks as companies and organizations are more likely to pay ransoms.
5. Cyber’s Weakest Link
The recent Snowflake data breach highlights a crucial cybersecurity lesson: human error is often the weakest link. This breach has put sensitive data at risk for many high-profile companies.
Introduction
How do you want to ‘spin’ venture investments for the past quarter? Do you want to focus on deal volume, capital investment dollars, mega-deals, or seed deals? Depending on your perspective, the outlook was either rosy or dour.
The optimists would highlight the more than 1,200 venture deals in the second quarter, down nearly 30% from 2023. However, investment dollars returned to pre-pandemic levels, led by 54 deals totaling more than $100 million, up 30% from the same period last year.
The mega-deals were supersized last quarter, with their average size tripling over 2023 and dollars accounting for almost 70% of total U.S. venture capital investment. Four ultra mega-deals of more than $1 billion accounted for nearly half of all venture investments. Wiz, which raised more than $1 billion in Q2 and soon after rebuffed a $23B acquisition offer from Google, was one of those Q2 mega-deals.
The story was much different on the early-stage end of the venture market. Seed deal volume dropped by 32 percent from 2023 but was slightly higher than Q1, hinting at an upcoming bounce from the bottom. Demonstrating its relative strength compared to the overall market, the news was better for cyber investment, which was basically flat—down only 1.7% – year-over-year and up significantly from Q1.
The complex venture market story can’t be told by just looking at the numbers. You have to go under the hood and evaluate the types of companies that have received funding, the markets they served, the investors who took money off the street, the types of investors (cyber vs. generalist), and the greater macroeconomic environment.
We take the quarterly deep dive to make sense of the data and provide perspective on the marketplace.
Q2 State of the Market – Cyber Deal Activity
In the second quarter of 2024, the venture market saw no reprieve from the macroeconomic forces that had plagued it in previous quarters. Venture firms set record highs of dry powder, neared record lows of deal volume, and waited in the wings for market uncertainty to ease. With rate cuts again postponed and the US presidential election looming, this may be further out than many believe.
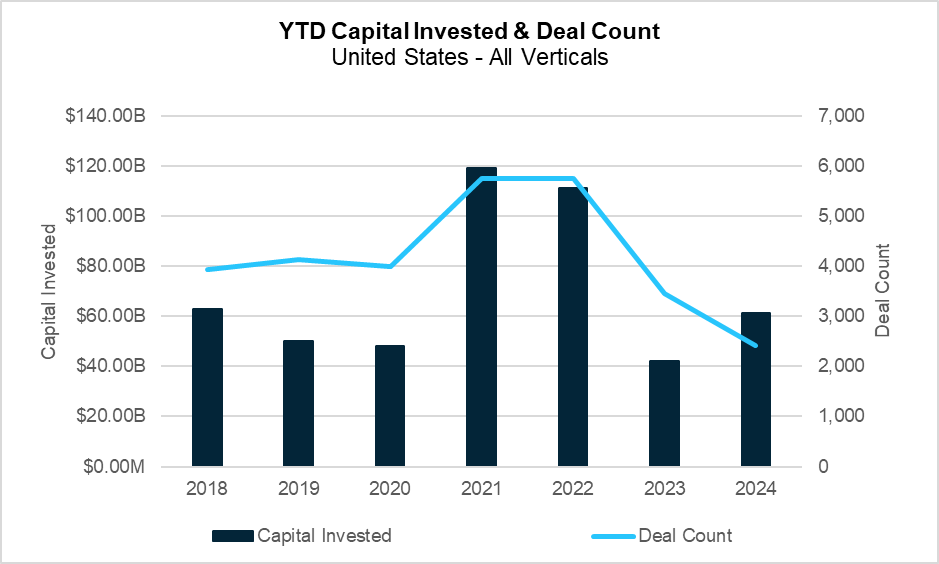
YTD Capital Invested and Deal Count (PitchBook)
Overall deal volume continued its decline year-over-year, from 1,715 deals in the second quarter of 2023 to just over 1,200 this quarter. While this is a marked increase from the previous quarter, year-to-date (YTD) totals are at the lowest seen since 2012. On the surface level, capital investment appears to paint a different picture, having rebounded more than 50% from the lows of 2023 back to pre-pandemic levels. However, this supposed recovery is misleading, as the majority of capital investment this quarter can be attributed to a handful of so-called “megadeals” – those investments of more than $100 million.
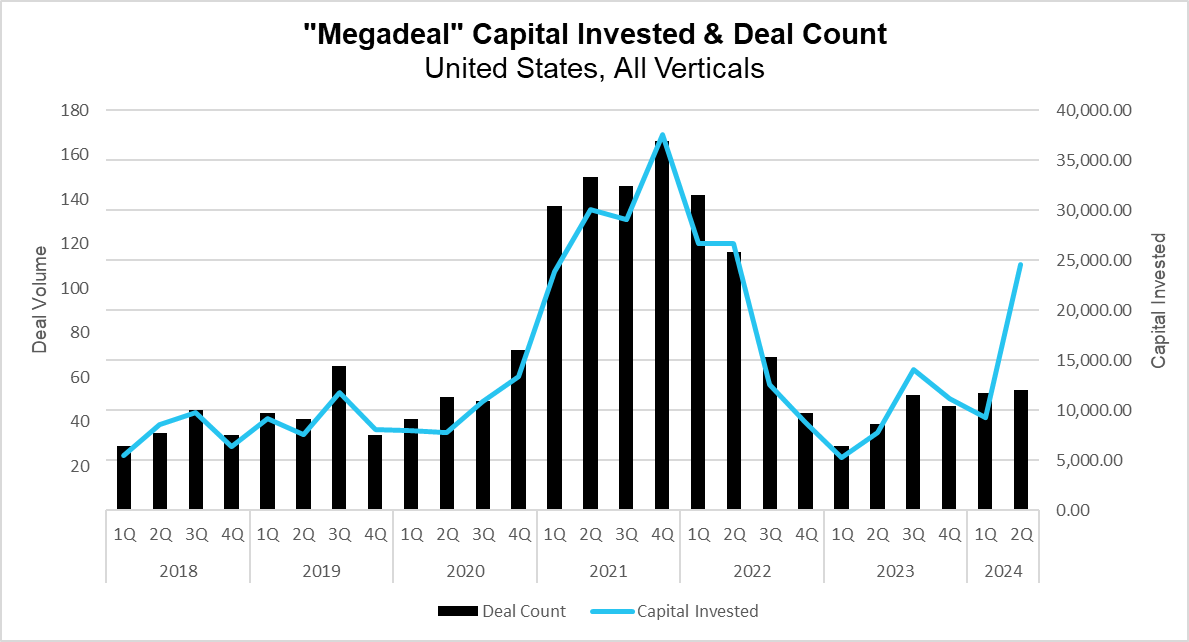
“Megadeal” Capital Invested & Deal Count (PitchBook)
This quarter saw 54 megadeals, an increase of around 30% from the second quarter of 2023. Despite this relatively modest increase in volume, the capital investment from these deals rose more than 310% over the same period, totaling nearly 70% of US venture capital investment during the quarter. The two largest of these deals, both in the Artificial Intelligence industry, rank among the five largest US venture deals in history, according to PitchBook. In addition, this quarter saw at least two other companies, including the cloud security phenom, Wiz, raise more than a billion dollars. Removing these four outliers would paint a different picture of the capital investment levels this quarter, as these deals alone accounted for $16.6 of the $36.8 billion invested.
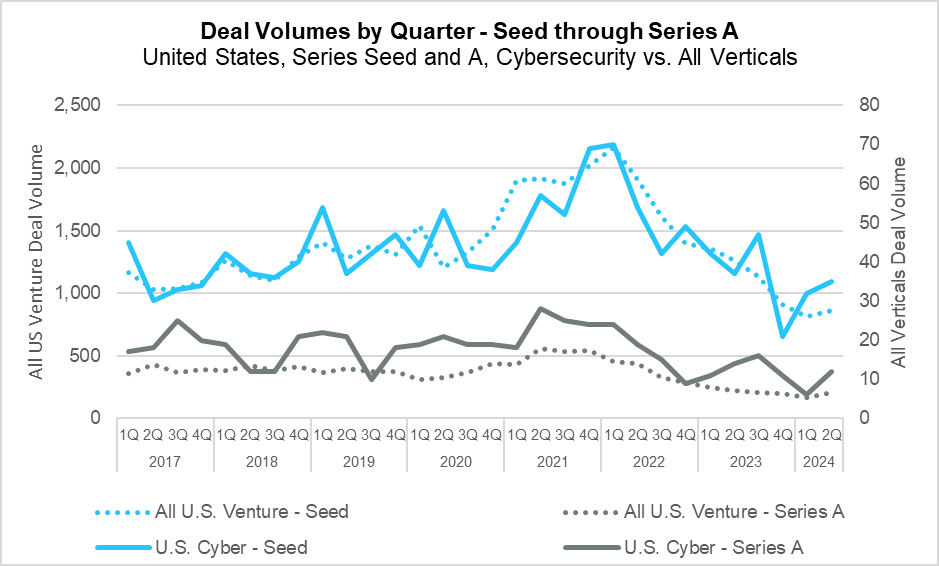
Deal Volumes by Quarter – Seed through Series A (PitchBook)
The second quarter of 2024 saw deal volume decline more than 25% year-over-year in the overall venture market. Much of this contraction happened in early-stage venture capital, with the largest decline coming at the seed stage. This pullback in seed round deals was significant, as overall deal volume dropped from 1,263 in the second quarter of 2023 to just 863 this quarter – a decline of nearly 32% year-over-year. Compared with the previous quarter, however, a slight recovery can be seen taking shape across all levels of early-stage capital, which had reached twelve-year lows in Q1. While the broader market retreated, the cybersecurity industry fared much better, seeing a dropoff of only 1.7% year-over-year and a noticeable recovery compared to the previous quarter’s lows.
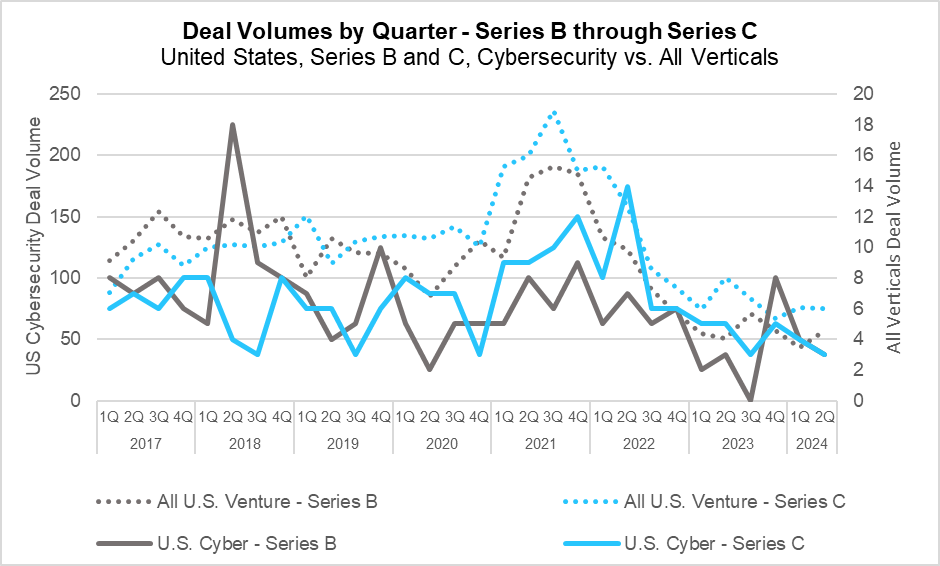
Deal Volumes by Quarter – Series B and C (PitchBook)
Series B and C deal volume saw mixed results in the second quarter. Series C deal volume was not immune to the broader market forces, posting a year-over-year decline of 25%. On the other hand, Series B deal volume increased slightly from 51 deals in Q2 of 2023 to 57 this past quarter. On a quarter-over-quarter basis, Series B outperformed the broader market even further, seeing an increase of more than 32% YoY. The cybersecurity sector saw little change by either metric, with Series C deal volume decreasing from 5 to 3 year-over-year and Series B staying flat.
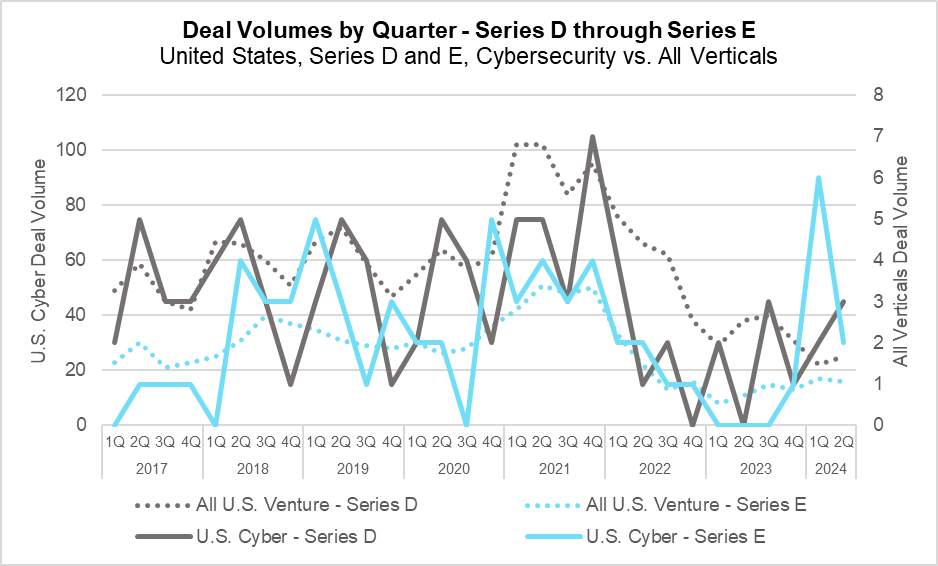
Deal Volumes by Quarter – Series C through Series E (PitchBook)
During the quarter, late-stage deal volume saw significant declines from the second quarter of 2023 – the lion’s share of this decline was felt at the Series D round, which fell more than 34% from the prior year. Despite this pullback, Series E deal volumes increased year-over-year, most likely due to an IPO market that continues to be muted. The cybersecurity industry again outperformed the overall market, seeing deal volume increase year-over-year at both the Series D and E stages. Cybersecurity companies were once again over-represented in Series E deals this quarter, representing the fourth largest category behind only Big Data, SaaS, and Telecoms.
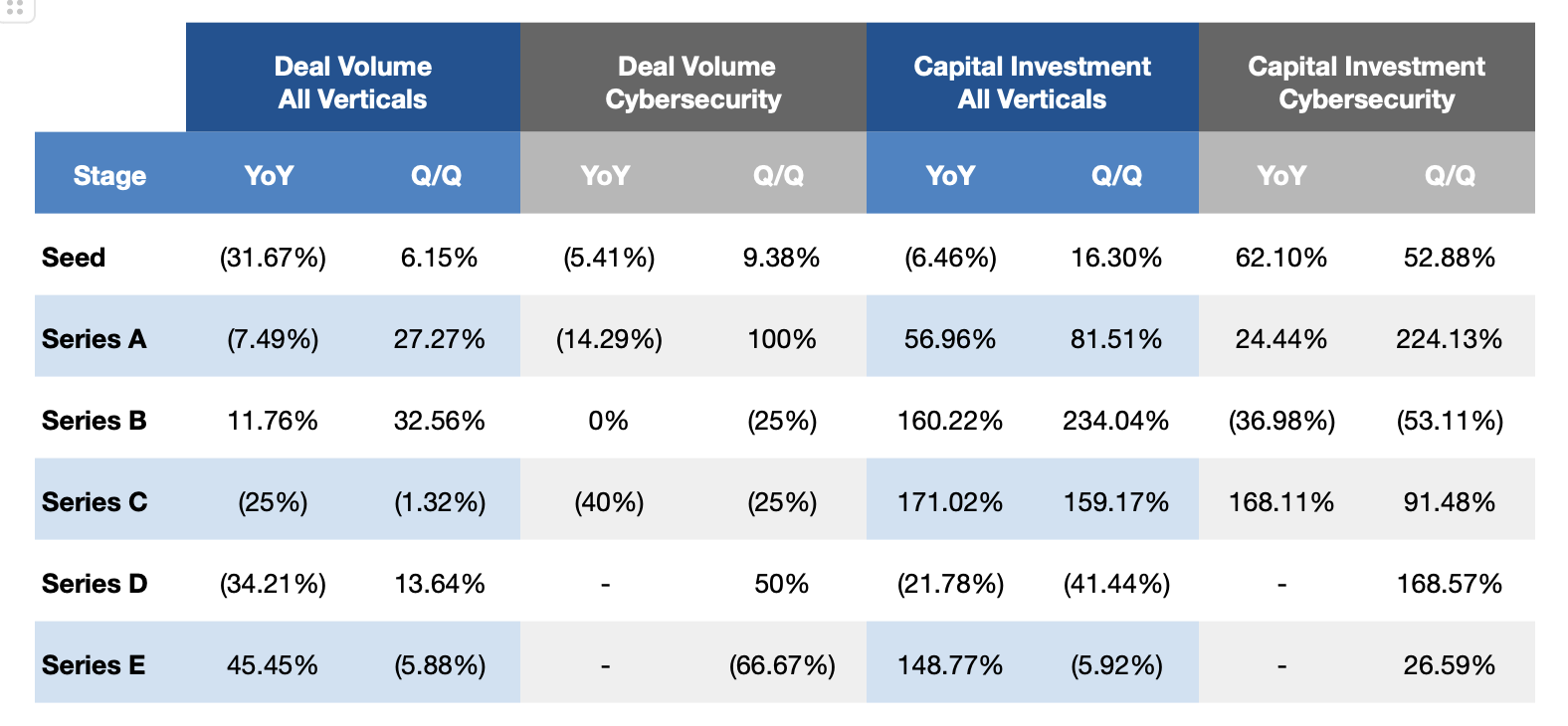
Q224 Deal Volume and Capital Investment Changes by Stage (PitchBook)
Note: Cells without data represent comparisons where there was no deal volume or capital investment in the referenced quarter.
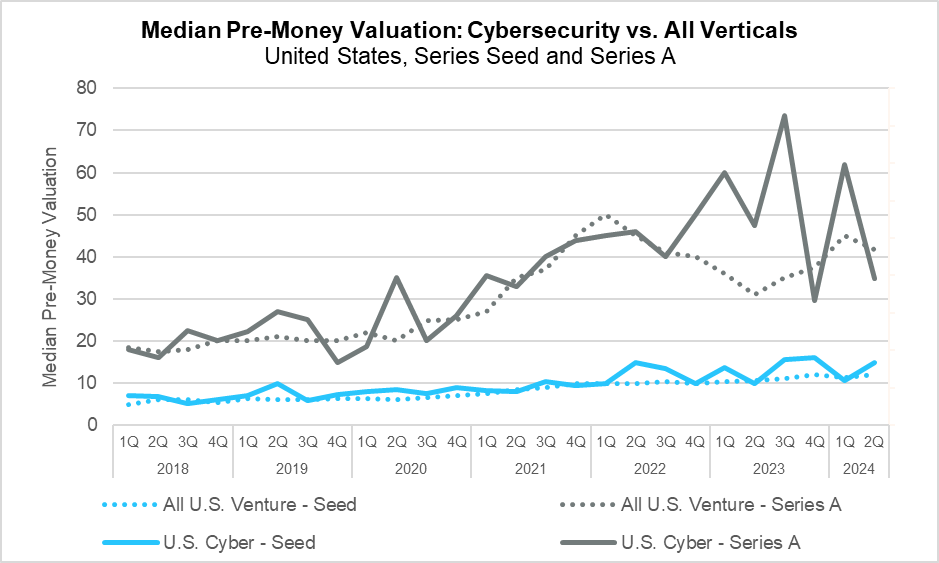
Median Pre-Money Valuation Seed and Series A (PitchBook)
In Q2, valuations saw mixed results throughout. Median pre-money valuations rose significantly across the spectrum of early-stage capital when measured year-over-year. This was particularly true of Series A valuations, which increased more than 25% over that period. However, as with deal volume, a quarter-over-quarter comparison shows much different results. In this case, Series A valuations pulled back from what had been their highest levels since early 2022. The cybersecurity industry showed different but mixed results, with year-over-year and quarter-over-quarter comparisons showing an increase in seed-stage valuations and significant declines in Series A valuations.
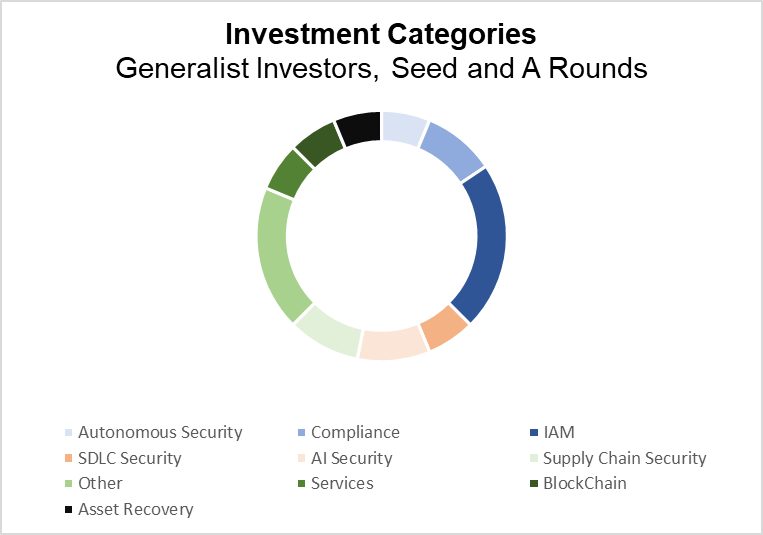
Investment Categories of Generalist Investors (PitchBook)
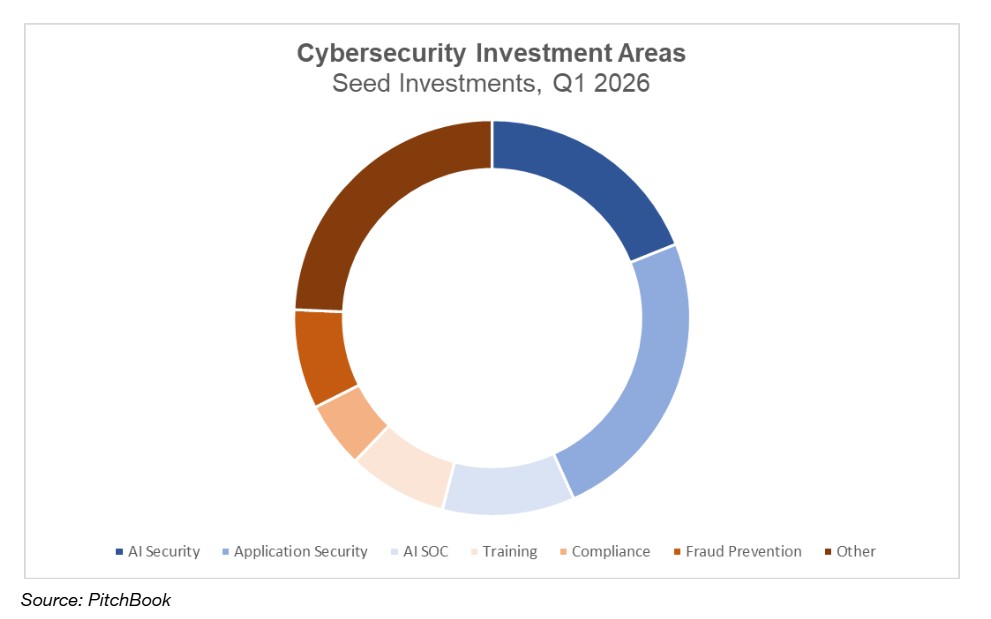
This quarter, we’ve opted to analyze the cybersecurity investment landscape at the Seed and Series A rounds by investor type (cyber-centric and generalist) to identify any differences in investment preference and trends around the newest companies in the sector.
The story of the quarter in the cybersecurity market was identity, with Identity and Access Management (IAM) solutions making up the largest category – nearly 25% – of the Seed and Series A deals within the sector. The next largest segment was Artificial intelligence, which has begun to fragment into two separate subcategories – Autonomous Security and AI Security – which are now reflected in our analysis. The first of these, Autonomous Security, covers any company using artificial intelligence as a tool for cyber defense. In the case of generalist investors, this was the smaller of the two categories, accounting for around 7% of their deals this quarter. The second, AI Security, covers companies aiming to secure LLMs and other AI tools. This may include identifying and preventing the upload of sensitive data or securing AI tools against model extraction attacks. This subcategory accounted for an additional 10% of the deal volume during the quarter. The next largest investment areas were supply chain security and compliance, accounting for nearly 10% each. A handful of other groups, namely blockchain, Software Development Lifecycle (SDLC) Security, and Services, comprised most of the remaining investments.
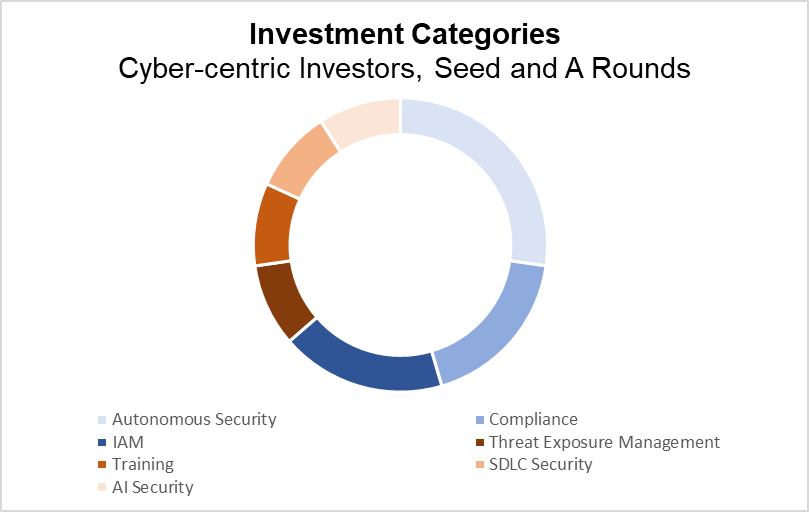
Investment Categories of Cyber-centric Investors (PitchBook)
While operating in many of the same categories as the generalist investors, cyber-centric investors emphasized different areas. For instance, their most significant point of emphasis this quarter was in Artificial Intelligence, where, notably, they opted to invest more heavily in Autonomous Security than AI Security, diverging from the broader investment market. Their next largest category was compliance – those companies aiming to assist others in complying with government regulations – which made up nearly 20% of their deal volume. Identity and Access Management was also a key segment for the cyber-centric investors, representing the third largest category and almost 20% of their deals this quarter. Finally, the remaining sectors in which these investors expended their capital this quarter were Training, Threat Exposure Management, and SDLC Security.
Note: Cyber-centric Investors are those VC firms with more than 50% of their completed deals involving a cybersecurity company.
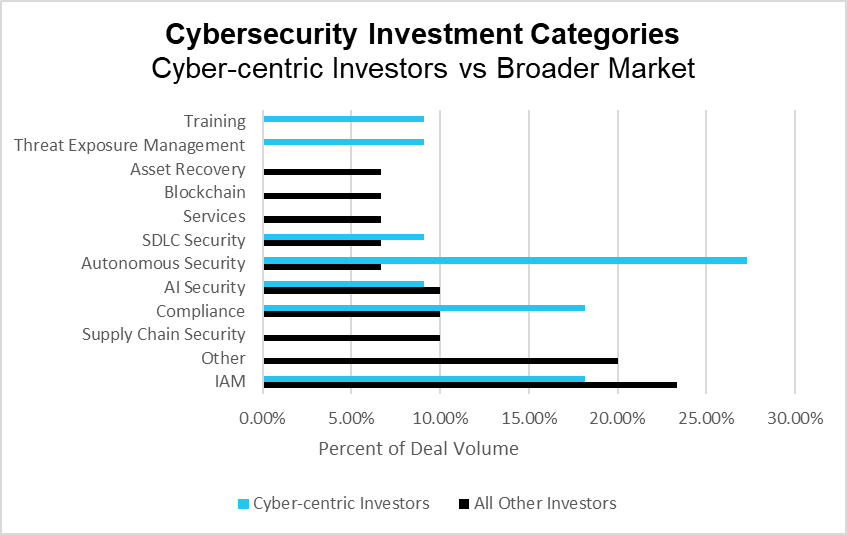
Cyber-centric Investors vs Broader Market (PitchBook)
Comparing the two types of investors shows significant overlap in the largest areas of investment – AI, Identity and Access Management, and Compliance – with substantial differences in the remaining categories. While these core areas overlap, there are clear differences in how the two investors approach them. In Artificial Intelligence, cyber-centric investors focused significantly more on Autonomous Security companies, while other investors slightly preferred AI Security. Similarly, in Identity and Access Management, cyber-centric investors focused more on securing the identity of applications and assets. In contrast, generalist investors were much more evenly split between those companies securing human identities and those focused on non-human identities.
Overall, the venture market remained stagnant in Q2, with a handful of megadeals offsetting near-record low volume and capital investment. While the cybersecurity vertical continued to fare better than the overall market, it was not immune to the macroeconomic conditions that dampened investment levels.
Git Me Some Crown Jewels: Code Repos Demand Special Attention
People often use the recipe for Coke as an example of a valuable trade secret, crown jewel data. In Q2, a company with eight times the market capitalization of Coca-Cola suffered a leak of its secret recipe, and the news barely made ripples in the security world.
Somehow, Google inadvertently posted a large trove of confidential technical documentation for their search algorithm on a publicly accessible GitHub repository. It didn’t take long for the documentation to be discovered and circulated. When you consider that over half of Google’s revenue still comes from Search, that Google’s search algorithm is responsible for routing billions of page views per day, and that over $50B per year is spent on search engine optimization to game Google, accidentally giving the world a decoder ring for its Search algorithm was a mind-boggling blunder.
What exactly happened? On March 13th, an automated process within Google published to GitHub sensitive internal documentation that explains much of how the secret Google search algorithm works. The automation released the docs under the Apache 2.0 open-source license as Google does with their public documentation. The error was fixed on May 7th when Google made another GitHub commit to make the documentation private. In response, Google tried its best to cast some uncertainty on the value of the documentation by cautioning against “making inaccurate assumptions about Search based on out-of-context, outdated, or incomplete information.” However, most industry experts agree that the documentation is authentic, relatively up-to-date, and supplies a significant amount of new insights into how Google Search works.
The preponderance of news coverage of this incident focused on the SEO side of the story: what SEO insights might be gleaned from the trove of leaked information and the fact that, for years, Google had been telling the industry that it did one thing, while in actuality doing something else – that everyone suspected they were doing. Astonishingly, very little coverage touched on what we saw as the main story: how could one of the most valuable, sophisticated technology companies on the planet, a company that billions of users entrust with sensitive data, make such a boneheaded mistake?
It’s unclear exactly why the automated process within Google malfunctioned. And, yes, accidents do happen. However, somehow, it feels that the scale of this incident has not been fully acknowledged – assuming it was not intentional. This DevOps mistake is on the order of the container ship knocking down the Francis Scott Key Bridge in Baltimore. This was not just an oops. A gap in Google’s controls allowed a data leak of the worst kind.
We assume that Google has conducted a substantial postmortem and made changes to ensure that control mechanisms are in place to avoid something like this happening again. Somehow, there was a co-mingling of automated management of crown jewel data and public documentation. Most likely, it was all the result of well-meaning engineers trying to be efficient and harmonize systems for managing docs. Public or private, a document is just a document, right? Just don’t mix up how you tag them.
Another important question we hope Google is asking themselves is why it took almost two months to discover and remedy the issue. We need to assume they fixed it as soon as they discovered it. So, for most of the 55 days that these docs were blowing in the wind, Google was likely unaware of the problem. Of any company on earth that has the capability to continuously scan GitHub (or the rest of the internet, for that matter) for proprietary data, it’s Google.
If you zoom out, this incident raises broader questions. How well do companies manage controls around using hosted code repositories like GitHub? As software development has moved to the cloud, code repos represent a key attack surface. By definition, the code and documentation hosted in a version control system like GitHub is intellectual property of some elevated importance. In many cases, it’s extremely sensitive. Are organizations implementing security controls around these repositories that are proportional to the risk?
While GitHub has improved its platform to make it easier for developers to lock down their repositories, modern-day DevSecOps involves a lot of automation that could simply have bugs or misconfigurations leading to disaster. Throw in late nights, tight deadlines, and a few inexperienced software engineers on the team, and it’s not hard to imagine intricate repository settings getting set up incorrectly.
Further adding risk, adversaries continuously scan public code repositories for developer slip-ups or laziness. Curious to see what would happen if he left a username and password in code checked into a public repository on GitHub, security researcher Chris Hays did just that as an experiment. Within 34 minutes of checking in his code with the exposed secret, someone tried to use the credentials to access the honeypot site Hays set up for the test. Thankfully, numerous secret scanning tools have emerged in recent years to help teams find secrets in their code before adversaries do.
Platforms like GitHub are just like any other cloud file storage and need to be properly secured. However, given the crown jewel nature of the data that reside in version control repos, the potential complexity of automation around them, and that they live in the fraught intersection between software engineering and security — where there can be a tension between security and development efficiency, code repositories represent an attack surface that demands special attention. None other than Google has shown us that.
Can You Hit the Brakes on a Runaway Train? CA Senate Bill 1047 Wants to Regulate AI
“The nine most terrifying words in the English language are ‘I’m from the government, and I’m here to help.’” While this 1986 quote from Ronald Reagan is undoubtedly tongue-in-cheek, the sentiment behind it is all too familiar in the tech industry, and we are seeing it play out in real time regarding artificial intelligence.
On May 21, the California State Senate passed California SB 1047, a bill intended to regulate companies developing “frontier AI models.” More specifically, should the bill pass the California Assembly in August before heading to Governor Newsom’s desk for signature, it will create a new state agency, aptly named the “Frontier Model Division,” responsible for establishing laws and safety standards. Among them are mandates that companies that spend more than $100 million on training a model (i.e., OpenAI, Anthropic, Google, and Meta ) must do safety testing or risk legal repercussions should said model be used to cause harm.
We sympathize with the situation legislators find themselves in; most people can probably agree that rules and basic safety standards are important, why else require seatbelts and airbags? But in the case of the freight train that is AI, SB 1047 missed the mark in two key areas: differentiating between model vs. application and trying to build tech regulation by taking a snapshot of a point in time.
The first key issue with the bill is also the heart of the bill, looking to provide regulation and oversight and place legal liability at the model level instead of the specific application of said models. This would be like holding an engine manufacturer responsible for someone putting their engine in a rocket. In the case of AI, this is meant to discourage a model from being used, for example, to create political deepfakes. Guardrails are still important but should be focused on key issues such as data privacy and security. These are obvious standards that all parties can get behind.
The second key issue with SB 1047 revolves around the current parameters that define which models and companies would fall under these new regulations. As mentioned, the current language reads that any model developed using 10^26 FLOPs (Integer Floating Point Operations per second) and costs over $100M to develop would fall under the new agencies’ purview. The problem with these parameters is that they do not have the flexibility to address the inevitable advancements we will see; it would surprise no one that a model costing $100M today will cost a fraction of that in 2-3 years. Additionally, by adding complexity, cost, and potential legal liability to model development, the proposed bill could stifle innovation by creating barriers that only the large tech can overcome.
So what does all this mean for us? It would be easy to read the above and interpret the idea that regulation is bad. This couldn’t be further from the truth. Government has an important role and needs to be a part of the conversation. In the case of SB 1047, a more collaborative and flexible structure should be put in place that addresses application vs. models, future advancements in computing efficiency and power, and core security and privacy. AI is not going anywhere: in 2023 alone, AI startups raised $50B, and despite what some proponents will have you believe, SB 1047 will not kill innovation, but it still has a long way to go to achieve its goals.
The Rising Cost of Ransomware and the Double-Edged Sword of Cyber Insurance
According to Sophos’ latest “State of Ransomware 2024” report, published in Q2, the median ransom payment in 2024 has surged to $2 million, a significant increase from the $400,000 average seen in 2023. This dramatic rise highlights the growing impact of ransomware. That’s an astonishing increase.
Ransomware attacks are an increasing threat to businesses. Cybercriminals are getting more sophisticated, fueled by factors like increased profitability and readily available tools on the dark web (RaaS). This allows them to launch more frequent attacks, exploit critical systems, and demand higher ransoms.
Cyber insurance can be a helpful tool for recovering from attacks but also contributes to the rise in ransom payments. The financial safety net it provides can make companies more willing to pay ransoms quickly, potentially inflating demands. Additionally, attackers might leverage the presence of cyber insurance during negotiations, demanding higher payouts based on perceived coverage amounts.
Beyond cyber insurance, other factors are driving up ransom costs. Attackers are increasingly targeting larger organizations that can afford to pay more. Their tactics are also evolving, such as locking data and threatening to leak stolen data, leading to higher recovery costs for businesses, even without paying the ransom.
The “Do Not Pay” pledge initiated by world governments in late 2023 discourages ransom payments, but it can be challenging for commercial entities to comply. Businesses face immense pressure due to potential service disruptions, lawsuits, and even life-or-death consequences in critical sectors like healthcare. This highlights the need for robust cybersecurity strategies to prevent attacks and minimize disruption in the first place.
The combination of smarter criminals, easier attack methods, and the potential for bigger payouts creates a perfect storm for businesses. Staying ahead of cyber threats requires constant vigilance and a robust cybersecurity strategy.
Snowflake Breach Shows How People Continue to be the Attack Surface
The recent Snowflake data breach highlights a crucial cybersecurity lesson: human error is often the weakest link. This breach has put sensitive data at risk for many high-profile companies. Major corporations like AT&T, Capital One, Doordash, Novartis, Okta, and others use Snowflake’s platform. Snowflake has notified around 165 organizations potentially exposed to these ongoing attacks.
According to cybersecurity firm Hudson Rock, the attack was attributed to a financially motivated threat actor group known as UNC5537. This group accessed data from various top-tier companies by exploiting compromised Snowflake customers’ user credentials. To obtain these credentials, attackers used infostealer malware, most likely distributed through social engineering attacks such as phishing or scareware. While the breach wasn’t due to a direct flaw in Snowflake’s systems, their pre-incident multifactor authentication (MFA) policy was flexible and optional, making them responsible for implementing and managing MFA settings. Ultimately, attackers stole credentials from accounts without MFA.
Several high-profile companies were affected. Ticketmaster and Santander reported significant data exposure. Pure Storage also confirmed that attackers breached their Snowflake workspace, accessing telemetry information like company names, LDAP usernames, and email addresses. More than 11,000 customers use Pure Storage’s data storage platform, including high-profile companies and organizations like Meta, Ford, JP Morgan, NASA, NTT, AutoNation, Equinix, and Comcast.
It’s a mess. Like with the MOVEit breach in 2023, focusing on systems that many large companies use to manage or store large amounts of data can result in a cascade in which many large firms are affected, dramatically amplifying the reach of the incidents.
The incident is also part of a broader pattern where inadequate MFA or human vulnerabilities have led to significant breaches. In April 2024, Change Healthcare experienced a ransomware attack exploiting the lack of MFA on critical servers, causing major disruptions in filling vital medical prescriptions. In 2021, Colonial Pipeline was breached due to a compromised VPN account without MFA, which led to widespread fuel shortages on the East Coast.
The methods used by attackers in this campaign remind us that cybersecurity isn’t just a tech problem—it’s a human one. As long as people are involved, attackers will find ways to exploit them. Generative AI is adding a new twist to social engineering attacks. AI can create highly convincing phishing emails, deep fake voices, and realistic impersonations, making it easier to deceive even well-trained individuals. For example, AI-generated emails mimicking a CEO’s writing style can trick employees into divulging sensitive information. Similarly, deep fake technology can simulate a trusted voice to gain unauthorized access.
As the stakes increase with breaches rippling across industries and having real-world consequences, we can expect more sophisticated and frequent attacks from financially motivated groups. This underscores the critical need for increased cybersecurity measures, including addressing human vulnerabilities and implementing MFA, to protect sensitive data and prevent future breaches.
To help us all remember, here’s a catchy public service announcement from CISA.