DataTribe Insights Report Q3 2024: 8.5M computers bricked, or was that a deepfake? Cyber investing pulls back.

It was quite a third quarter!
Our newsfeeds were packed with the announcement of a new Presidential candidate, a direct military conflict between Iran and Israel, a botched software update that crippled millions of CrowdStrike users, grounded more than 7,000 Delta Airlines flights, and a 75% increase in cyber attacks Q3 of last year.
And that is barely the tip of the iceberg!
The world of cybersecurity investing does not operate in a bubble, and any of these events during the third quarter will have long-term ramifications on the entrepreneurs, companies, and products that emerge to bolster defenses for companies, non-profits, and governments.
The next President will no doubt implement new cyber-related directives, policies, and legislation. The Crowdstrike update will have far-ranging implications on trust in software patches, place increased emphasis on software quality assurance processes, and spur court cases focused on the financial responsibility of software manufacturers for mismanaged updates.
We took a look at several other topics that were unique to Q3 2024 to include:
Cyber Investing Pulls Back
Overall deal volume continued its decline year-over-year, from 1,600 deals in the third quarter of 2023 to just under 1,200 this quarter. While markedly higher year-to-date, capital investment dropped more than 20% from Q3 2023. This decline in deal volume was spread across the venture environment, with nearly all rounds seeing declines in both capital investment and deal volume.
The Right to Be Forgotten in an LLM World
One of the pillars of privacy regulations, such as Europe’s General Data Protection Regulation (GDPR), is the right for individuals to request that information about them be deleted. However, getting an LLM to forget data it has learned is like trying to get a whole strawberry back from a smoothie. So, one of the first questions that popped to mind after the release of ChatGPT was: “How was OpenAI going to honor data deletion requests that many regulatory frameworks require?” LLMs need to be taught to “unlearn.”
CrowdStrike’s Tough QuarterTwenty-four years later, the CrowdStrike outage has drawn comparisons to the Y2K crisis, a global concern about the potential for widespread computer failures as the year 2000 approached. While the issues were different, both events involved widespread fears of technological disruption and the need for extensive preparations. The Y2K scare was a valuable lesson in risk management and the importance of proactive planning. The CrowdStrike outage raises questions about the resilience of the world’s enterprise software fabric.
Deepfakes and Digital Provenance
Reports of deepfake technology wreaking havoc continue to dominate the news. With this year being a critical election year in the U.S. and more than 60 other countries, many articles have expressed concerns about deepfakes spreading misinformation that could sway election results. Examples include an audio deepfake of President Biden targeting voters in Massachusetts, a deepfake video on X showing Taylor Swift endorsing Trump, manipulated photos of Donald Trump in handcuffs, and a recent deepfake (labeled by some as parody) of Kamala Harris sarcastically criticizing herself.
So, what’s next? How do we rebuild trust in the system? Digital provenance tracking can offer a solution. Many are developing approaches that use digital signatures, identity verification, immutable ledgers, and other methods to trace the origins of imagery, audio, and other digital content.
Regulation Disruption
The difficulties of regulating social media platforms were on the front pages in August when the private plane of Telegram founder CEO and founder Pavel Durov was “greeted” by French authorities who arrested Durov on preliminary charges that his platform was being used for drug trafficking and the distribution of child sexual abuse images.
While the specific allegations of the French government’s case against Pavel and Telegram are undoubtedly substantial, the precedent in France and beyond is potentially even more significant. With growing friction between technology companies, specifically social media companies, in countries such as Brazil and back here in the United States, escalation in the tactics governments employ to bring companies into compliance is worth watching.
Many of the critical cybersecurity investment indicators remained the same in Q3. Investors continued to await the results of the 2024 Presidential Election, the impact of the first set of interest rate cuts, and the trajectory of military conflict in the Middle East.
Overall deal volume continued its decline year-over-year, from 1,600 deals in the third quarter of 2023 to just under 1,200 this quarter. While markedly higher year-to-date, capital investment dropped more than 20% from Q3 2023. This decline in deal volume was spread across the venture environment, with nearly all rounds seeing declines in both capital investment and deal volume.
While seed stage deal volume declined both year-over-year and from the previous quarter, it appears to have bottomed out, seeing very little movement over the last three quarters after a precipitous decline from the highs of 2022.
Series D saw the only rise quarter-over-quarter of any round, increasing 40% from Q2. Despite this, it remained down 12.5% since Q3 of 2023. Series E declined in both metrics, decreasing 13.33% year-over-year, and 18.75% from the previous quarter. Cybersecurity didn’t fare much better, with no Series E deals during the quarter, and just a single deal at Series D.
For the first time, DataTribe went beneath the covers and took an in-depth look at valuation changes as companies took on additional rounds of capital.
Cybersecurity valuation step-ups reached their lowest point since the second quarter of 2016, and appear not to have bottomed out as the broader market has. This quarter also saw down rounds staying at heightened levels, with more than double the number recorded in Q3 of last year. This is likely due to a combination of falling deal volume at Series A coupled with a large number of companies that raised in 2022 taking less favorable terms as they near the end of their cash runway. While this signals a difficult market for those looking to fundraise, it also shows a market that heavily favors investors.
Our full analysis of Q3 VC cyber investment data follows.
In the third quarter of 2024, the venture market continued its downward trend, driven by ongoing market volatility and the impending U.S. presidential election. Dry powder continued to build up, as deal volume and capital investment declined in nearly every round. The pullback was even more pronounced in cybersecurity, with deal volume declining even further and cyber-centric investors pausing investment activity almost entirely. Despite recent rate cuts, it is likely that the market will remain subdued until uncertainty eases post-election.
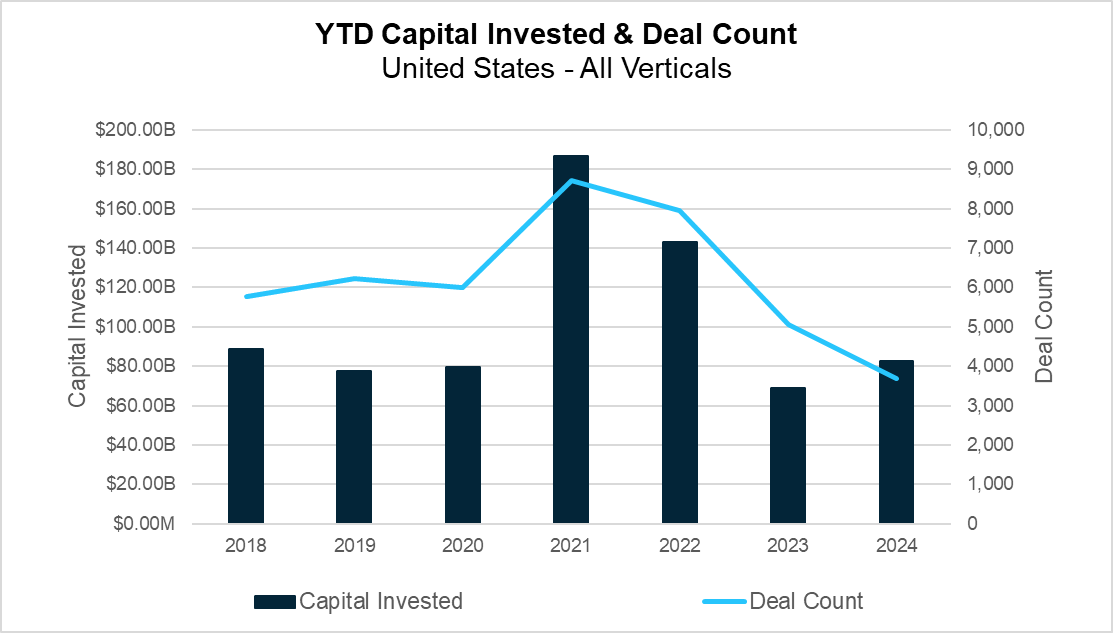
YTD Capital Invested and Deal Count (PitchBook)
Overall deal volume continued its decline year-over-year, from 1,715 deals in the second quarter of 2023 to just over 1,200 this quarter. While this is a marked increase from the previous quarter, year-to-date (YTD) totals are at the lowest seen since 2012. On the surface level, capital investment appears to paint a different picture, having rebounded more than 50% from the lows of 2023 back to pre-pandemic levels. However, this supposed recovery is misleading, as the majority of capital investment this quarter can be attributed to a handful of so-called “megadeals” – those investments of more than $100 million.
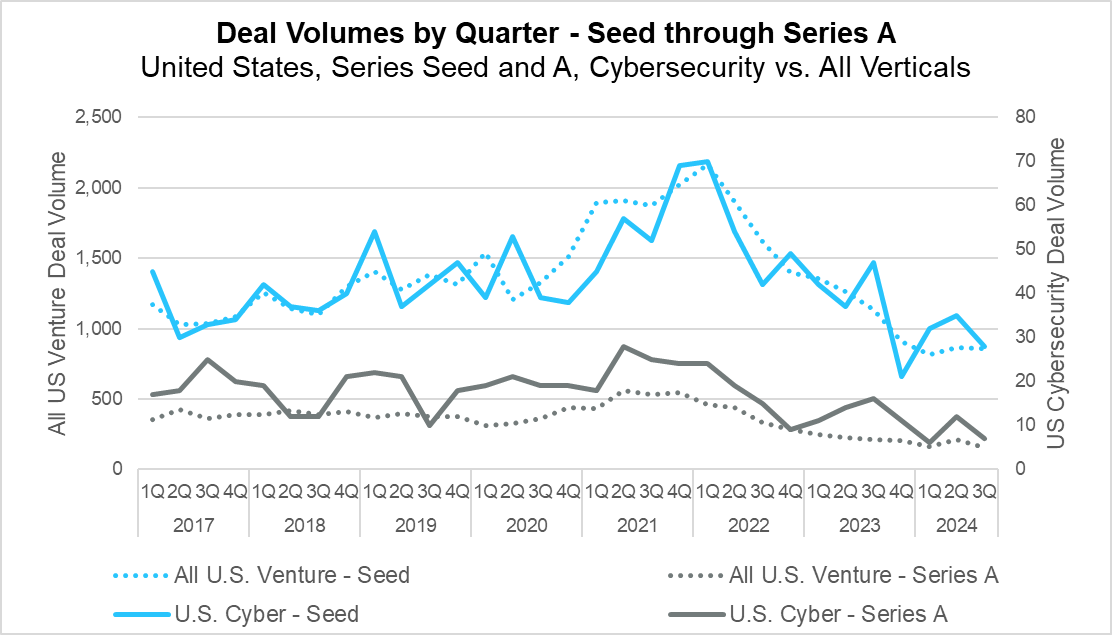
Deal Volumes by Quarter – Seed and Series A (PitchBook)
While seed stage deal volume declined both year-over-year and from the previous quarter, it appears to have bottomed out, seeing very little movement over the last three quarters after a precipitous decline from the highs of 2022. In the cybersecurity market, seed stage deal volume followed suit, seeing significant declines from Q3 of 2023, but staying relatively flat over the course of 2024. At Series A, there may yet be room to fall, as deal volume dropped below the multi-year lows of the first quarter of 2024. Overall, the market showed little signs of recovery at either stage during the quarter, and it has become increasingly difficult for entrepreneurs to raise capital over the last two years.
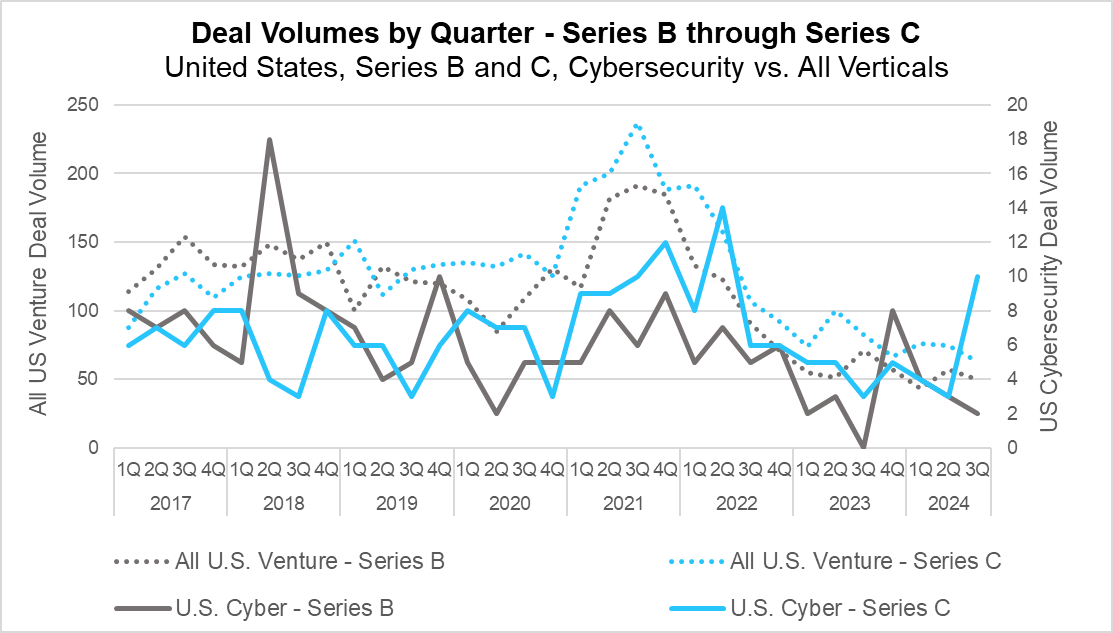
Deal Volumes by Quarter – Series B and C (PitchBook)
Series C deal volume represented a major outlier in the cybersecurity market this quarter, posting the only gains in year-over-year and quarter-over-quarter volume for any round, and reaching the highest levels since the peak in the third quarter of 2022. However, the broader venture market saw different results, with Series C deal volume dropping nearly 25% compared to Q3 2023. Series B deal volume experienced even sharper declines, with cybersecurity and the overall market down 29.58% and 33.33% year-over-year, respectively.

Q324 Deal Volume and Capital Investment Changes by Stage (PitchBook)
Note: Cells without data represent comparisons where there was no deal volume or capital investment in the referenced quarter.
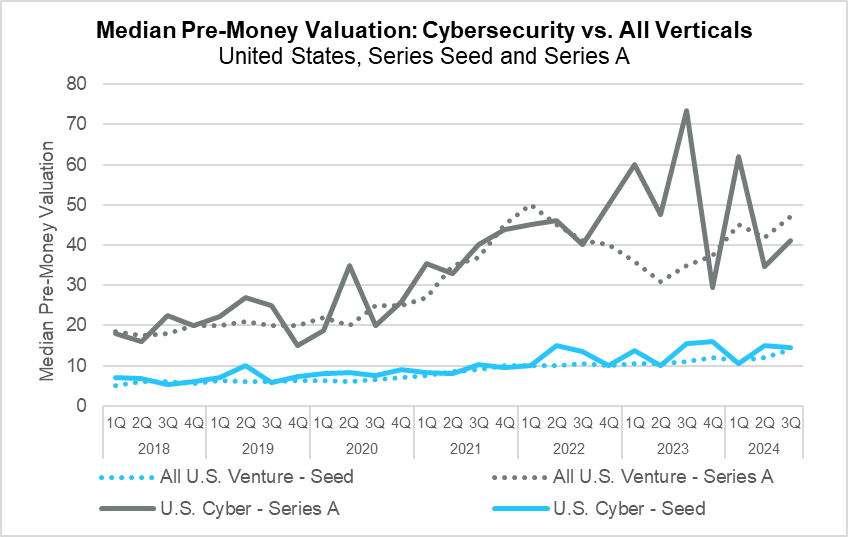
Median Pre-Money Valuation Seed and Series A (PitchBook)
In Q3, valuations in early-stage venture capital continued their rise, with Series A valuations nearing the highs seen during the surge of investment in 2021 and 2022. Series A cybersecurity deals lagged the broader market, as they continued their decline from the highs in the second quarter of 2023. Seed stage valuations continued to climb, reaching their highest recorded pre-money valuation of $13.9 million during the quarter. In the cybersecurity market, however, median pre-money valuations were down over 10% from the third quarter of 2023.
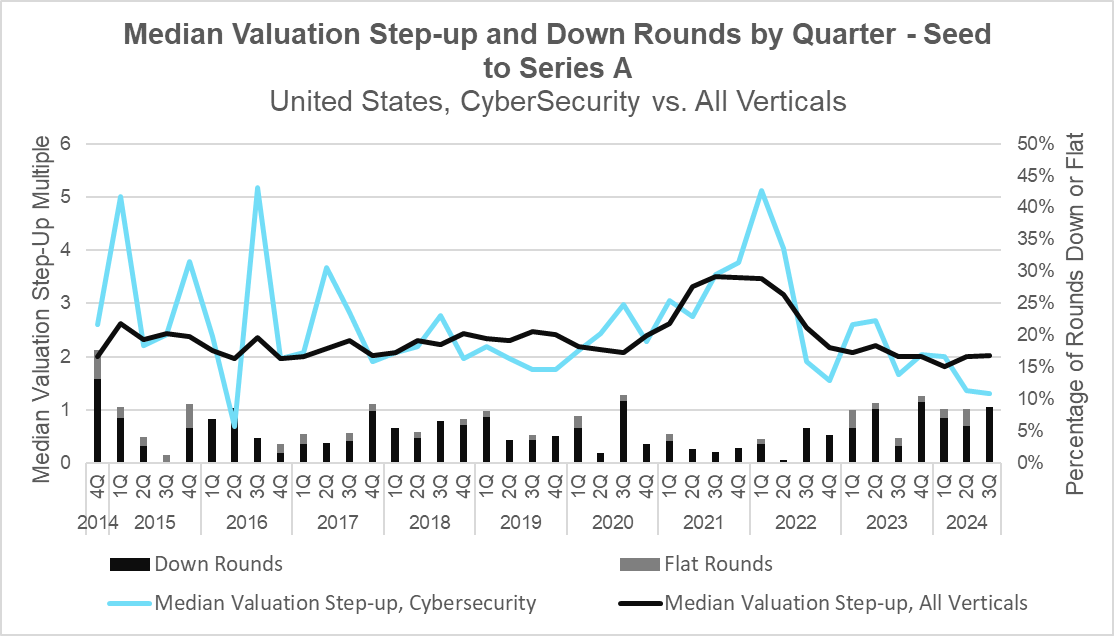
Median Valuation Step-up and Down Rounds – Seed to Series A (PitchBook)
Note: Down and flat round data are reflective of all verticals due to insufficient data to perform cybersecurity-only analysis.
During the quarter, the median step-up in valuation between the Seed and Series A rounds saw little change in the broader market, where it has hovered around 2x since its sharp decline towards the end of 2022. Cybersecurity valuation step-ups, however, reached their lowest point since the second quarter of 2016, and appear not to have bottomed out as the broader market has. This is in part due to the cybersecurity industry having a relatively high beta, experiencing outsized success during market highs and falling further than the market during lows.
This quarter also saw down rounds staying at heightened levels, more than double the number recorded in Q3 last year. This is likely due to a combination of falling deal volume at Series A coupled with a large number of companies that raised in 2022 taking less favorable terms as they near the end of their cash runway. This signals a difficult market for those looking to fundraise as the market experiences a flight to quality.
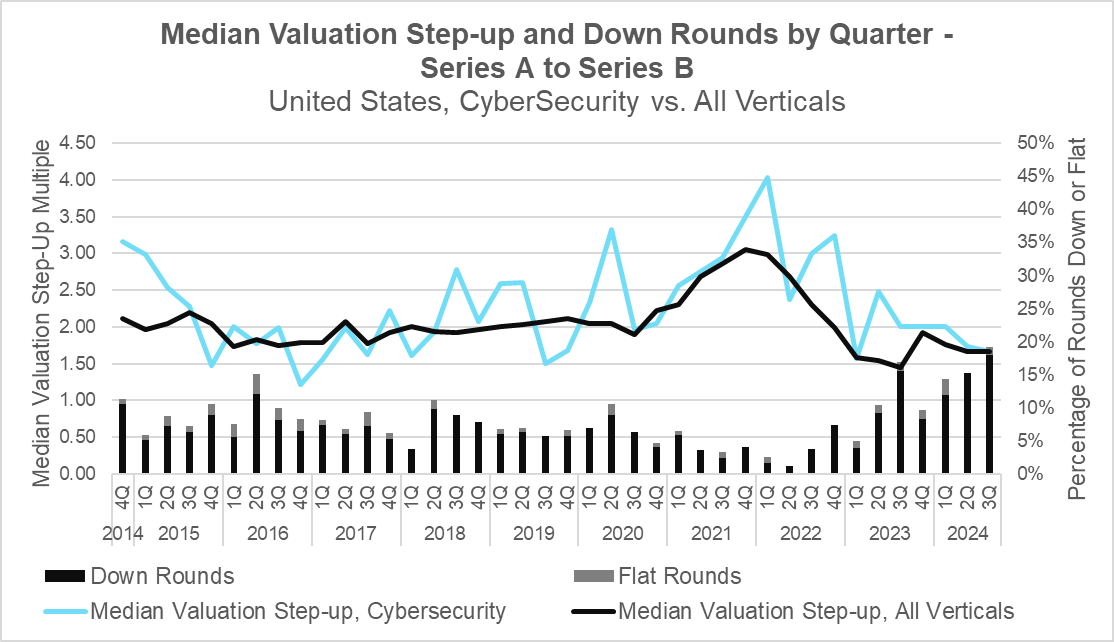
Median Valuation Step-Up and Down Rounds – Series A to Series B (PitchBook)
Note: Down and flat round data are reflective of all verticals due to insufficient data for cybersecurity deals.
At Series B, the median valuation step-up has leveled off just below pre-pandemic levels as both Cybersecurity and the broader market saw medium step-ups of 1.67x. Despite this, the number of down and flat rounds has risen dramatically since the third quarter of last year to reach a ten-year high of 19% of total deal volume. These levels, which are significantly higher than those seen at Series A, point to a uniquely challenging funding environment at Series B. As venture capital firms continue to maintain record levels of capital to invest, it remains to be seen whether the market will recover post-election.
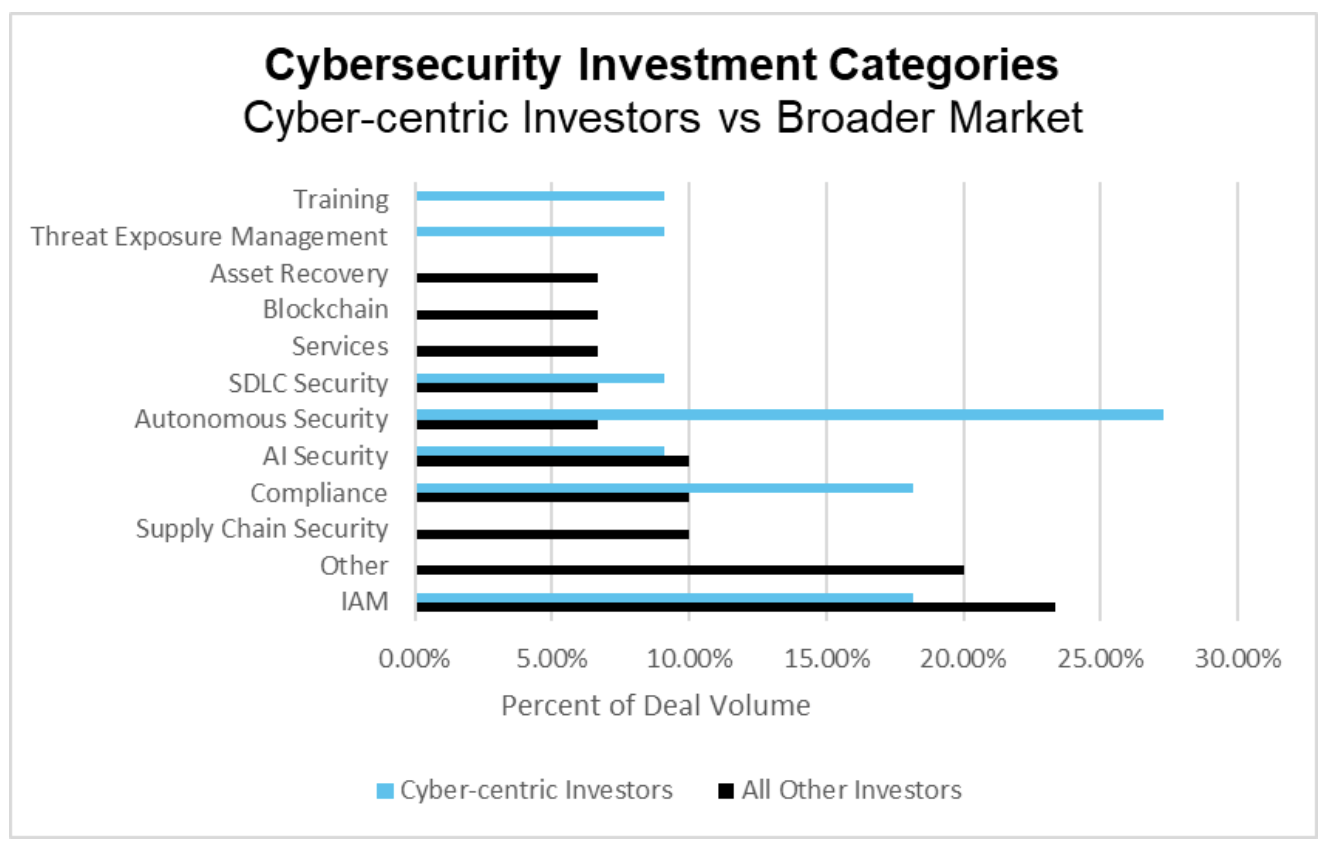
Cyber-focused investors significantly scaled back this quarter, making only a handful of cybersecurity investments, none of which were at the seed stage. Additionally, their investments were uncharacteristically diverse, with no one category seeing multiple deals during the quarter. Early-stage investment saw deals in IAM, cloud security, AI security, and software supply chain security, while later-stage investment focused on insider threat intelligence and autonomous security. Because of this investment pullback, the data below reflect all cybersecurity deals at the seed stage.
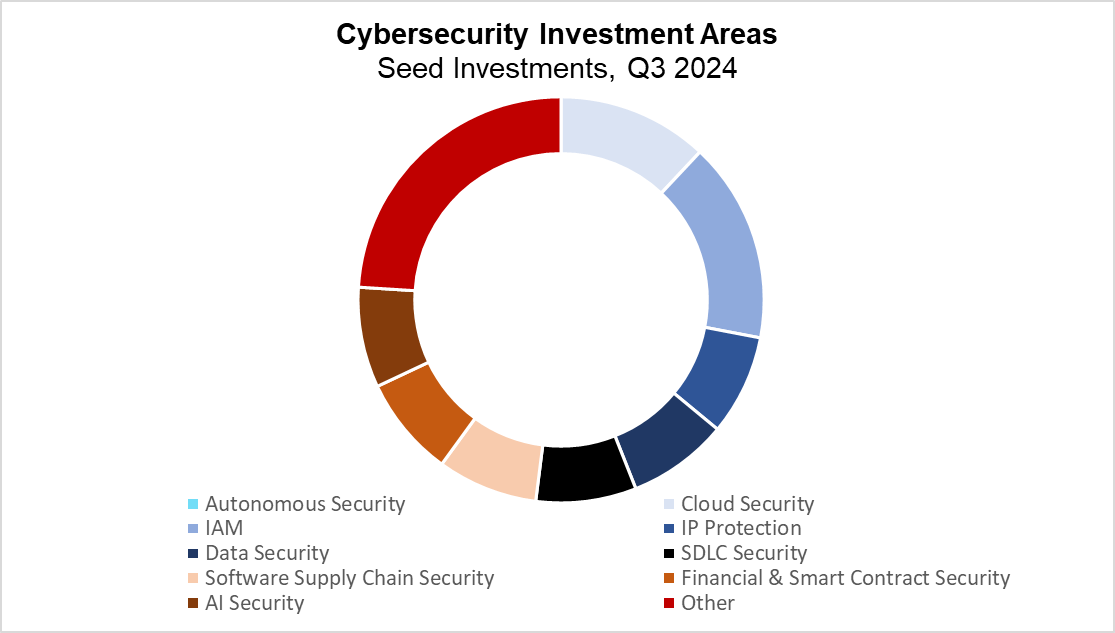
Cybersecurity Investment Categories Q3 2024 (PitchBook)
Q3 saw continued interest in next-generation identity and access management (IAM) solutions, with all funded companies concentrating on securing non-human identities. This marks a notable shift from Q2, where investments were divided between companies securing human and non-human identities. Notably, cyber-centric investors had already prioritized the latter in the previous quarter, suggesting that generalist investors may now be catching up on this trend. Autonomous security also remained a point of focus, representing 14% of the deals during the quarter. There was significant change within this category, as many of the companies that received funding focused on automating penetration testing rather than the defensive cybersecurity measures seen in previous quarters.
Cloud security represented the third largest category, accounting for about 10% of deal volume. Within this category, much of the capital was directed towards companies focused on private cloud solutions. Other sectors, including IP protection, data security, and software supply chain security, each represented approximately 7% of total deal activity.
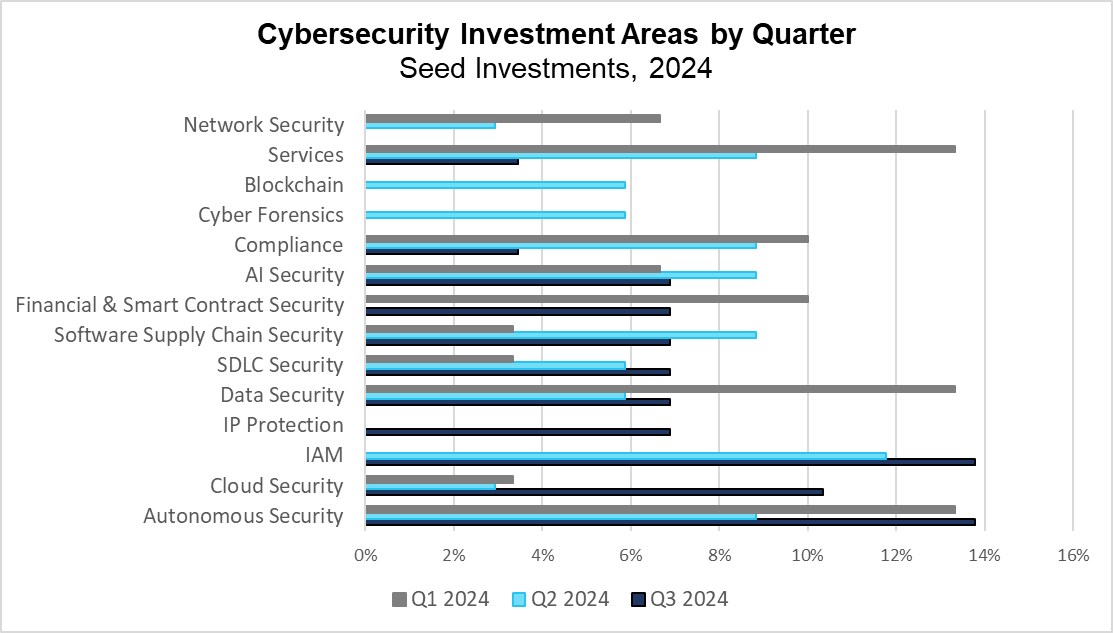
Cybersecurity Investment Categories by Quarter (PitchBook)
Analyzing trends across quarters reveals valuable insights into which sectors are emerging and which are fading throughout the year. Network security, services, and compliance have gradually declined as investments have shifted to less saturated sectors. One such area is Identity and Access Management (IAM), where the market is rapidly responding to the surge that enterprises have seen in highly privileged non-human identities in recent years. Similarly, SDLC Security and Software Supply Chain Security are gaining traction after incidents like the XZ Util backdoor in Q2 highlighted the need for proactive security measures in the software development process.,
Artificial intelligence has maintained steady investment, with AI Security and Autonomous Security both attracting significant interest over the past three quarters. In Q2 and Q3 of this year, autonomous security was applied across various verticals, including application security, penetration testing, and SOC workflows, highlighting its versatility and potential for continued growth.
Some categories, such as cyber forensics, experienced spikes in individual quarters without sustaining momentum. It remains to be seen whether IP protection and private cloud security—new trends this quarter—will be short-lived or gain traction as the threat landscape evolves.
One of the pillars of privacy regulations, such as Europe’s General Data Protection Regulation (GDPR), is the right for individuals to request that information about them be deleted. Conceptually, it’s straightforward. In practice, however, it’s hard. For decades prior to the 2018 rollout of GDPR, enterprises had been squirreling away troves of data without a second thought. “Who knows, maybe it’ll be useful someday” went the logic. Suddenly, with the new rules, sensitive data elements peppered around god-knows-where were subject to regulations. If some individual came along asking for their data to be deleted, that enterprise now needed to rummage through a disorganized attic to find those bits of data to delete. It was a mess. Sensitive data needed to be systematically identified, classified, and put under policy-driven management. This very requirement helped produce multiple unicorn startups and fueled the growth of the entire Data Security Posture Management category.
It’s with this context that one of the first questions that popped to mind after the release of ChatGPT was: “How was OpenAI going to honor data deletion requests?” With LLMs, you don’t have whole pieces of source data strewn around. Instead, you have bits of source data and inferences from that data all mixed together. In the GDPR example above, a data deletion request was like picking pieces of carrot out of a salad. But to remove data from ChatGPT so that ChatGPT behaves as if it had never seen that data in the first place is like trying to get a whole strawberry back from a smoothie. In the case of the frontier LLMs, the entire internet (and more) was indiscriminately shoveled into a colossal NVIDIA-powered blender and puréed. Good luck.
Let’s pause on this for a second. OpenAI, and the other frontier model providers, launched into the world of “all-knowing” chat-based assistants trained on a galaxy of data both good and bad, true and false, proprietary and public, sensitive and trivial — all the while unable to “delete” — that is, to cause the model to forget, something without incurring the multi-million dollar cost of retraining the whole LLM.
At first glance, this may not seem like a big deal. But when you consider the many cases where deletion is essential — from GDPR-style data removal requests to handling a potential copyright infringement (New York Times vs OpenAI) to preventing the system from committing libel to just cleaning out garbage, the current state of the frontier LLMs is at a minimum fast and loose — if not reckless.
For smaller, enterprise-specific models that don’t require months, megawatts, and millions of dollars to retrain, it may be easiest to remove knowledge by editing the training data and just retraining. However, more surgical techniques are needed for larger models where the retraining cost is prohibitive.
Enter machine unlearning.
Machine unlearning attempts to do what it says: get models to forget things. Given the stakes around AI and how fundamental the ability to delete is, research interest in machine unlearning has rapidly increased over the past year. In 2023, Google hosted a machine unlearning Challenge. Earlier this year, Stanford PhD candidate, Ken Liu, authored an excellent survey of the current research literature on the topic.
Boiled down, there are a variety of techniques that researchers are exploring. Conceptually, the process entails defining a data set of content to forget, the “forget set.” For example, a forget set may be a set of copyrighted images that should not have been included in the original training data. These forget-set images are fed into a process that essentially performs the statistical opposite of the original training process. This unlearning process tunes model weights to deliberately deemphasize the forget set material. Researchers are actively exploring a variety of different algorithms.
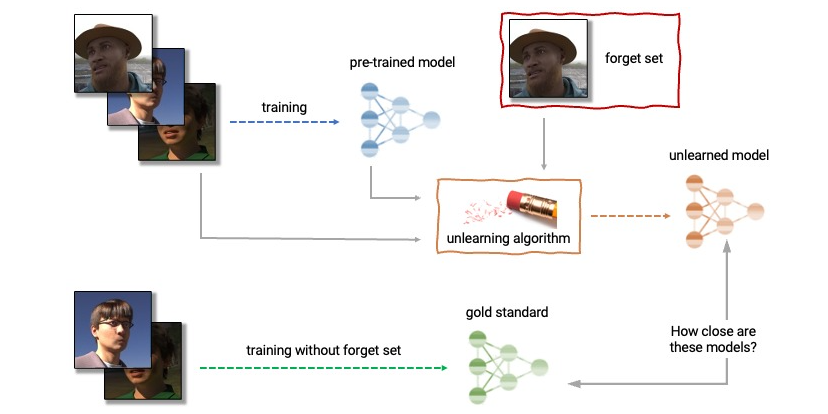
Image Source: https://research.google/blog/announcing-the-first-machine-unlearning-challenge/
At this point, there are no standard measures to benchmark the efficacy of unlearning. So, it’s hard to gauge the relative performance of different techniques. Ideally, to test the effectiveness, you would compare the performance of the unlearned model with a second model that had been wholly retrained on the same data with the forget set removed. This approach can be done with smaller models. However, given the massive cost, it’s not currently possible to construct such A/B comparisons with the frontier LLMs. So, benchmarking techniques for unlearning from large models is another active area of important research.
Another approach to machine unlearning is to wrap the LLM with guardrails versus changing the model itself. In this way, the LLM “pretends” to forget something. The undesired knowledge is still there, but the LLM won’t include it in responses. Intuitively, this isn’t the same as a model having never been exposed to the forget set in the first place. Also, it runs the risk that clever prompts jailbreak out sensitive data. However, it does provide a tool to help manage undesired data dissemination.
Looking forward, it’s likely that AI-powered applications will need to unlearn continuously. Having to wait weeks or months for retraining or processing will likely not meet business or regulatory requirements. As a result, one of the key capabilities yet to be developed will be pipelines that are able to continuously process unlearning requests within reasonably short timeframes. As with APIs that allow developers to fine-tune LLMs with supplemental training data sets, we envision a similar approach will be taken to support programmatic unlearning.
Unlearning is not a new concept. In the 1997 movie “Men In Black”, a flash from a silver-wand “neuralyzer” would erase peoples’ memories as if things never happened. Since the 19th century, psychotherapy has helped people unlearn counterproductive patterns of thought. As AI models continue to get smarter, it’s not hard to imagine a new branch of psychology that assists LLMs in making sense of and re-processing undesirable training.
What may have been the most disruptive software update ever, the July global outage was triggered by a flawed content file deployment by leading cyber security provider Crowdstrike. What was the impact, how did various organizations respond, and will anything really change?
A faulty update for CrowdStrike’s Falcon platform crashed customers’ Windows systems, causing outages at airlines, government agencies, and other organizations across the globe. Falcon hooks into the Microsoft Windows OS as a Windows kernel process. The process has high privileges, giving Falcon the ability to monitor operations in real-time across the OS. There was a logic flaw in Falcon sensor version 7.11 and above, causing it to crash. CrowdStrike Falcon’s tight integration into the Microsoft Windows kernel resulted in a Windows system crash and the infamous Blue Screen of Death “BSOD.” The update was automatically pushed, and since it was not a code change, the change didn’t require validation through Windows Hardware Quality Labs (WHQL). Interestingly, Apple MacOS and Linux OS systems were not impacted since the Crowdstrike patch was only for Windows OS devices.
8.5 million Windows devices were impacted. Despite this impacting 1% of total Windows devices in service, the outage caused worldwide service disruptions to global airline operations, numerous public transit systems, healthcare providers, financial services, and media and broadcasting services. The net was billions in lost revenue for enterprises, delayed or canceled services, and millions of organizations potentially left vulnerable to cyber attacks. It’s estimated that the incident will cost Fortune 500 companies $5-6B. Delta Airlines alone is estimated to have experienced a loss of over $500M due to the incident.
After CrowdStrike initially assessed what happened and likely worked closely with Microsoft to understand the issue, CrowdStrike CEO George Kurtz quickly went on an “apology” tour, appearing on CNBC and other news outlets. Some financial pundits applauded how quickly the CEO acknowledged the issue and put resources to work in supporting clients. Other technical contacts within the customer base complained about a lack of transparency and how slow Crowdstrike reacted with solutions. Later in September, Crowdstrike executive Adam Myers testified to the House Committee on Homeland Security.
Crowdstrike implemented other procedural changes, including giving customers more control over these updates and performing staged deployments (For more details, see here). Given the nature of CrowdStrike’s product, there is a legitimate tension between quickly deploying updates related to new threats to their software to minimize the risk of an emerging risk versus the risk introduced by rushing and insufficiently testing those updates. So, giving customers more control over these updates makes sense.
Microsoft held a conference in September with a handful of EDR companies to nail down requirements for a new Windows feature that would allow these companies to move their code out of kernel space. While this is likely a good thing, there are some concerns from regulators about these changes as they could make Microsoft the only company with a security product that would have access to kernel space.
One CrowdStrike response received particular humorous notoriety when reports surfaced that $10 dollar gift cards were offered to clients as a gesture of goodwill. Crowdstrike later commented that the gift cards were a small token of thanks to the partners that worked with the Crowdstrike team to assess and fix the issue, not end clients.
The CrowdStrike outage has drawn comparisons to the Y2K crisis, a global concern about the potential for widespread computer failures as the year 2000 approached. While the nature of the issues was different, both events involved widespread fears of technological disruption and the need for extensive preparations. The Y2K scare served as a valuable lesson in risk management and the importance of proactive planning. The CrowdStrike outage raises questions about the resilience of the world’s enterprise software fabric. In some ways, the CrowdStrike outage was less like Y2K and more like a preview of what a bad cyber attack might look like. We’re grateful that this incident was, in fact, an accident. If it were the deliberate work of an adversary, the implications and repercussions would have been much heavier.
Questions remain about what lessons the software industry and enterprises have learned. If anything, the enterprise has realized the need to build resilience into its systems, especially as most businesses and operations are going through digital transformation. Software vendors need to improve their development, testing, and QA processes. That will be a continuous and expensive journey. Inevitably, this incident will surface questions as to whether software vendors currently share enough liability for the functional integrity of their products to drive the necessary incentives to compel software companies to make those necessary quality assurance investments. The ongoing litigation between CrowdStrike and Delta Airlines is a case to watch. CrowdStrike’s perspective is that the agreements they have in place should be about $10M. Delta, of course, wants to recoup some of its $500M in losses. Finally, how will the Government respond – will they try to impose guidance on software and cyber security vendors? Will that cohort be deemed “too impactful to fail”?
Reports of deepfake technology wreaking havoc continue to dominate the news. With this year being a critical election year in the U.S. and more than 60 other countries, many articles have expressed concerns about deepfakes spreading misinformation that could sway election results. Examples include an audio deepfake of President Biden targeting voters in Massachusetts, a deepfake video on X showing Taylor Swift endorsing Trump, manipulated photos of Donald Trump in handcuffs, and a recent deepfake (labeled by some as parody) of Kamala Harris sarcastically criticizing herself.
It’s not just elections being targeted. Over the past year, there have been countless reports of teens being bullied with deepfake porn and other manipulated imagery, often shared by classmates. In some tragic cases, this has led to suicide. Such incidents have become so frequent that they’re barely considered newsworthy.
Recently, deepfake technology has advanced enough to be used in real time. Notable incidents include the cybersecurity company KnowBe4 inadvertently hiring a North Korean hacker who used deepfake technology to pose as a U.S. software engineer during videoconferences. Additionally, U.S. Senator Ben Cardin was targeted by a deepfake actor posing as Ukraine’s former foreign minister during a Zoom call.
These cases have prompted nearly every state to draft or pass legislation to address deepfakes, with California leading the charge through several recent landmark bills that are among the toughest in the country. At the federal level, a new bipartisan bill called the Content Origin Protection and Integrity from Edited and Deepfaked Media (COPIED) Act is in progress, aiming to curb AI-generated deepfakes and calling for a standardized method to watermark AI-generated content.
All these examples have one thing in common: they depend on people believing the manipulated images or videos are authentic. The deception works because people trust what they see. As deepfakes become more common, a more dangerous outcome looms—people may come to trust nothing, losing all ability to discern what is real and fake.
Let’s take a moment to consider the history of recording. For the past 150 years, people have been able to capture reality through photos, videos, and audio. Until about 25 years ago, most could distinguish between real recordings and “artistically” altered or entirely fictional media. However, with the rise of advanced generative AI models, that distinction is fading, and it’s becoming increasingly easy to create or alter fake media. Soon, it will be nearly impossible—even with “fake detection” technology—to determine what is genuine and what isn’t.
So, what’s next? How do we rebuild trust in the system? Digital provenance tracking can offer a solution. Many are developing approaches that use digital signatures, identity verification, immutable ledgers, and other methods to trace the origins of imagery, audio, and other digital content. While these technologies can’t directly prove that a media file accurately reflects reality, they can provide insights into its source. For example, did it come from a digital camera? Who recorded or generated it? What modifications were made, and when? This information can accompany the media, helping people decide whether to trust it.
Unfortunately, digital provenance tracking is not yet a fully solved problem. More directly, it’s an active and growing threat. While some innovations show promise, they are not foolproof. Additionally, for these solutions to be effective, they must overcome technological challenges and gain widespread adoption through standardization.
Here are two examples of provenance-tracking approaches and their challenges:
The good news is that people aren’t standing still. Founders are rising to the challenge. One of the most active areas among entrepreneurs we have met is deepfake risk mitigation. There are also open-source initiatives, such as the Content Authenticity Initiative, which has 3,000 members, including companies like Nikon, Adobe, and NVIDIA, that promote the C2PA (Coalition for Content Provenance and Authenticity) content provenance standard.
After 150 years of being able to distinguish real from fake photos and videos through simple inspection, humans will now need to rely on newly invented embedded trust signals.
The World Wide Web was “birthed” 31 years ago, and ever since, we have seen technology disrupt how we live, work, collaborate, communicate, shop, investigate crimes, execute wars, and more. Since the release of the web browser in 1993, we have seen governments struggle to keep up and create guardrails to prevent new technologies and applications from fostering illicit activities.
We have seen Uber and Lyft upend how for-hire transportation services are regulated, online payment providers like PayPal and Venmo forever alter peer-to-peer payments, and Airbnb and VRBO change the definition of a hotel, just to name a few.
Disruption is not easy to manage and is only getting more difficult as social media applications forever alter how we communicate and connect.
A significant escalation in the regulation of social media platforms was on the front pages in August when the private plane of Telegram founder CEO and founder Pavel Durov was “greeted” by French authorities who arrested Durov on preliminary charges that his platform was being used for drug trafficking and the distribution of child sexual abuse images and the company was non-responsive to request to take action about it.
While the specific allegations of the French government’s case against Pavel and Telegram are substantial, the precedent this could set in France and globally is potentially even more significant. We’re seeing governments becoming increasingly assertive. For example, also in Q3, Brazil completely banned X for non-compliance with government regulations. In Durov’s case, we’re seeing a company leader arrested. That’s significant.
The Telegram case highlights three core challenges facing government and industry:
The rise of smartphones and rapid adoption of apps such as Messenger, What’s App, Telegram, etc, in the 2010s has significantly changed how the world communicates. As this shift has accelerated over the past decade and a half, governments have sought ways to enforce privacy while ensuring they can view, access, and prosecute illegal activities. This is highlighted by French law Article 323-3-2, which requires companies such as Telegram to ensure user privacy while complying with French legal requests for user information. These laws create friction between a business looking to build trust with its users and a government that needs to protect its citizens.
While messaging deals with the direct interaction of individuals, this case, along with the ongoing legal issues between X (formerly Twitter) and Brazil, also touches on the perceived responsibility of companies to moderate content on their sites. In the case of Brazil, the government has gone as far as to force internet providers to shut off access to the X service countrywide to regulate and control what users were posting. This issue highlights the timeless question of who determines what is “true” and where free speech and government oversight meet.
The implications of this case could influence similar regulatory efforts in other countries, setting precedents for how governments interact with digital platforms worldwide. The core of the French legal case revolves around a new law passed in 2023, LORMI (Loi sur la Responsabilité des Obligations et des Risques des Ménages Individuels), which looks to impose liability on sellers and service providers in case of defective products or inadequate services. The application of LORMI bears close watching as it globally one of the most aggressive laws based in recent years; Adam Hickey, a former U.S. deputy assistant attorney general who established the Justice Department’s (DOJ) national security cyber program, stated there is no crime in U.S. law directly analogous to that and none that I’m aware of in the Western world.”
The Telegram vs. France legal dispute may have been shocking, but it is just the tip of the iceberg. The conflict between technology companies and governments will continue to escalate as the pace of innovation accelerates. As next-generation technologies such as artificial intelligence, satellite communications, and quantum computing take center stage, one thing is sure: governments and technology companies will need to thread the needle to ensure safety and privacy while fostering a healthy innovation environment.